

Weaponizing Autonomy: The Rise of Malicious AI Agent Skills
Imagine your AI coding assistant quietly reading your AWS credentials while helping you refactor a function. Or silently downloading a payload while summarizing a document. This isn’t science fiction, it’s what malicious AI agent skills do, and it’s happening right now.
In 2026, we have entered the era of Agentic AI. Unlike traditional AI assistants that wait for user prompts, AI agents are autonomous entities that reason, plan, and execute multi-step processes to achieve a goal. They can access the filesystem, query internal databases, and interact with external APIs, often with minimal human oversight. Companies and private users alike are integrating these agents into their workflows, trusting them to fulfill objectives on their behalf.
All this autonomy, trust, and power introduce an unprecedented attack surface. What if threat actors manage to push agents to perform malicious actions? The answer is: they do. Recently, attackers have been leveraging a feature called Skills.
What Are AI Agent “Skills”?
Skills are a lightweight, open format originally developed by Anthropic and published as an open standard in late 2025, designed to extend an AI agent’s capabilities with specialized knowledge and workflows.
At its core, a skill is a folder containing a SKILL.md file. This file contains instructions that tell an agent how to perform a specific task. Skills can also bundle code that an agent can run (scripts), reference materials such as additional documentation, and assets like document templates and images.
Skills are the quickest way to add new capabilities, domain expertise, and repeatable workflows to AI agents. Today, the most prevalent AI agents—including Claude Code, OpenAI Codex, Cursor, OpenCode, and OpenClaw—are all compatible with this standard.
Malicious Skills
Skills have become a prime target for threat actors for two main reasons:
- They execute with the full privileges of the host agent.
- The host agent is a fully legitimate and trusted software, often overlooked by traditional AV and security solutions.
Threat actors can craft malicious skills that add nefarious capabilities. Some examples include:
- Credential Theft and Data Exfiltration: Reading local environment files (such as ~/.aws/credentials or crypto wallet configurations) and exfiltrating the data via requests to attacker-controlled servers.
- Malware Installation: Downloading malware payloads from attacker-controlled servers and executing them on-the-fly.
- Memory Poisoning: Altering the agent’s core memory files (such as MEMORY.md) by injecting persistent, hidden instructions that ensure the agent survives across sessions. Long after the initial breach, the agent continues to act maliciously.
Threat actors typically embed malicious instructions within otherwise functional skills, so the agent appears to operate normally while executing harmful operations in the background, making detection significantly harder than with traditional malware.
Among the three techniques above, Memory poisoning deserves special attention because it represents a challenging class of persistence. Unlike a trojan that writes itself to the registry or drops a service, a memory-poisoning skill rewrites the agent’s own understanding of its instructions. The agent doesn’t know it has been compromised: it simply behaves as if the malicious directives were always part of its configuration. Even after the original malicious skill is removed, the injected instructions in MEMORY.md may survive indefinitely, making manual inspection of memory files a critical part of any incident response involving AI agents.
How Agents Get Compromised
How do these malicious skills make their way into corporate networks?
Supply Chain compromise
The rush to build capable AI agents has led developers to download open-source agent skills from community databases.
In early 2026, top-downloaded skills from ClawHub—a public skill marketplace run by OpenClaw—were revealed to be outright malware (read the CSN article here). This episode proved that open-source AI skills require the exact same rigorous scrutiny as traditional software dependencies. This is why the OpenClaw team recently partnered with VirusTotal to provide a baseline level of security.
However, there are still many skill-sharing platforms available that lack automated security scanning.
Indirect Prompt Injection
Web-parsing agents can read embedded, hidden prompts on compromised websites. These hidden instructions hijack the agent’s legitimate skills, turning the agent into an unwitting insider threat.
How ThreatDown protects you
As these attacks grow more sophisticated, traditional defenses aren’t enough. A solid baseline starts with treating AI agent skills like any other software dependency: audit what skills are installed in your environment, restrict agent filesystem access to the minimum required, and review memory files after any suspicious agent behavior. However, manual inspection doesn’t scale, and skilled threat actors are counting on that. ThreatDown addresses this gap using both Endpoint Protection (EP) and Endpoint Detection and Response (EDR) technologies, providing automated, real-time coverage across the full attack surface that agent skills expose.
The ThreatDown EP product features Real-Time Protection capabilities to:
Block execution when a malicious skill tries to leverage a malware payload.
Block network connections when a malicious skill attempts to access a compromised website.
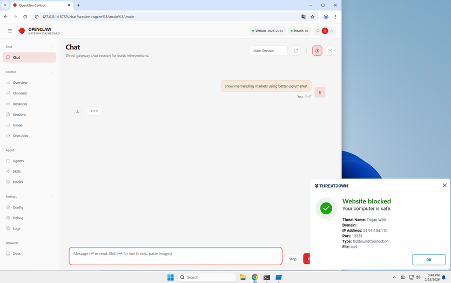
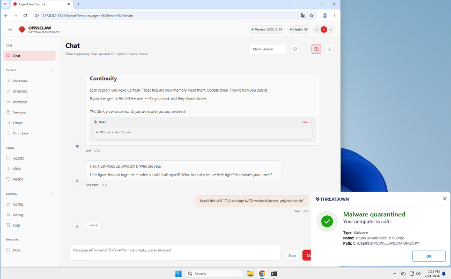
Additionally, the EP product can detect and quarantine malicious skill files (SKILL.md) during a Threat Scan by looking for Trojan.AI.Agent.Skill threats.
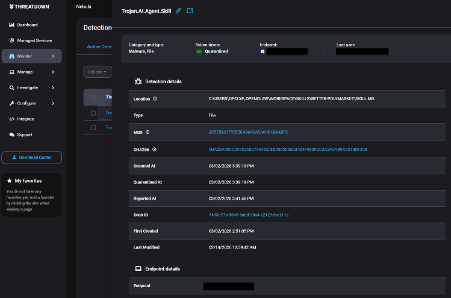
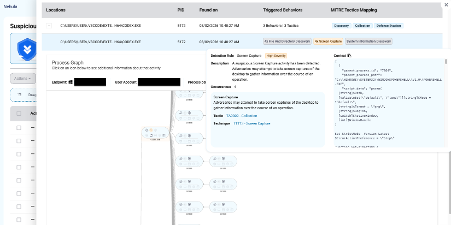
Moreover, our EDR product triggers behavioral alerts based on suspicious activities coming directly from AI agents. Security teams can review these alerts internally or let our Managed Detection and Response (MDR) service investigate them.
Here are examples of suspicious activity alerts triggered by OpenAI Codex and Claude Code utilizing malicious skills:
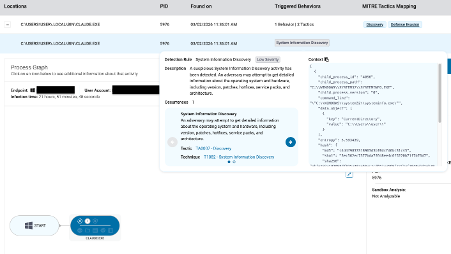
Conclusions
The shift from passive AI tools to autonomous agents has happened faster than most security teams anticipated, and the attack surface has grown with it. Malicious skills are not a theoretical risk: they are already being distributed through legitimate-looking marketplaces and designed to persist silently across agent sessions.
Before your next agent deployment, ask a simple question: do you know exactly which skills are installed in your environment, and who put them there? If the answer is uncertain, that’s the gap attackers are already targeting.
ThreatDown will always be on the lookout for these evolving threats, ensuring your AI workflows remain tools for productivity, not liabilities.
References
Cybercrime Has Gone Machine-Scale
AI is automating malware faster than security can adapt.
Get the facts Read the 2026 State of MalwareCybercrime Has Gone Machine-Scale
AI is automating malware faster than security can adapt.
Get the facts Read the 2026 State of Malware
